

Introduction
In the realm of modern medicine, it may feel like there is a new drug hitting the markets every day, but in actuality, the process of drug discovery is much more daunting than it may seem.
The traditional path to developing new drugs is often lengthy and expensive, consuming billions of dollars and years of research. The formulation of feasible drugs is especially pressing for progressive diseases, which tend to worsen over time and affect millions worldwide, leaving patients and families searching for hope amid limited treatment options.
Alzheimer’s disease is known as one of the most prevalent (and currently incurable) progressive diseases, characterized by the death of brain cells and the destruction of a person’s memory. In the more serious stages of the condition, individuals with Alzheimer’s lose the ability to effectively respond to their environment. As researchers strive to uncover effective therapies, they have turned to machine learning—particularly, generative models—to reshape their approach.
One of the most significant hurdles in developing potent treatments for Alzheimer’s is the blood-brain barrier (BBB), a highly selective barrier that both protects the brain from harmful substances and complicates the delivery of therapeutic drugs. Typically, a drug intended to combat Alzheimer’s must cross this barrier, but optimizing a drug to permeate the barrier largely compromises its efficacy.
Several mechanisms of drug passage (besides simple diffusion), structural modifications of drugs, and the structure of the BBB must be studied, making the discovery of a drug to cure Alzheimer’s disease immensely complicated. This is where several machine learning technologies and models, such as GANs, can be used to facilitate drug discovery.
Generative Models and Their Use in Drug Modeling
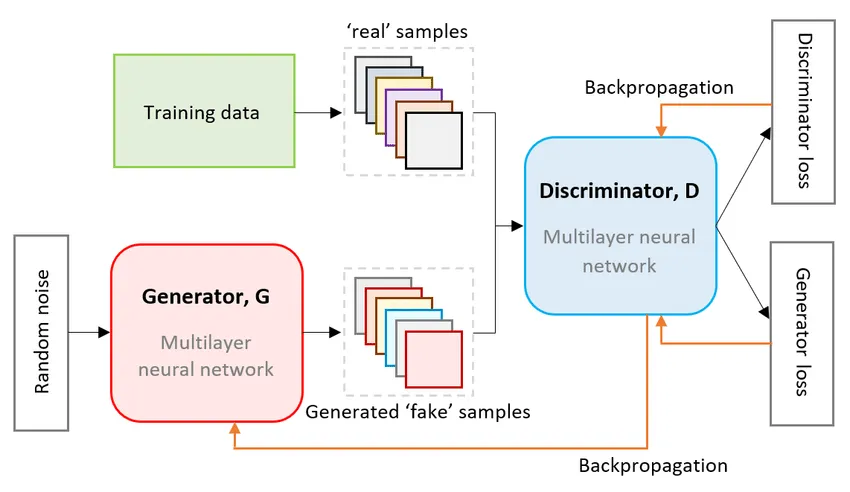
One popular generative model, a model that understands how a specific set of data is generated, is a Generative Adversarial Network (GAN). The structure of a GAN consists of two main components: a discriminator and a generator. As their names suggest, the generator will generate possible arrangements of data—in this case, possible drug molecules—and analyze both real and generated data to discern the generator image from the real data. Think of it as trying to find the fake paintings in a set of fake and real paintings. You, acting as the discriminator, are fed both fake data—the generator’s generated paintings—and real paintings, which is the actual collected data.
These models work in a feedback loop; as the discriminator identifies the generator’s data arrangement, the generator will improve its data arrangements so it will be harder to detect the next round. Thus, as you find fake paintings, the following fake paintings will become more realistic, making it difficult to discern them from the real data. This feedback loop continues until the discriminator produces data that appears so realistic that the discriminator can no longer detect a difference between the real data and the generated data.
In relation to the drug development for Alzheimer’s, its real data contains the chemical structures of previously discovered drugs. Meanwhile, the generator will produce possible alternate combinations of chemical structures to create new drugs. The discriminator, trained on the real data, will attempt to find faults within the generator-created molecules and report loss values, which generates an accurate data set of drugs to be sent through the testing process.
The Future and Drawbacks of GANs
The concept of generative models has been around for a while, but industries still put in billions of dollars to further research in their field due to its vast amount of applications. Specifically, GANs have been integrated with other deep learning models, providing protection against common issues found with using solely GANs, such as a lack of diversity within generated data. Additionally, benchmarking systems—processes used to “score” the model’s performance—are incorporated, comparing aspects such as accuracy, latency, and memory usage.
Moreover, experimentation with the use of quantum computing has led to the efficient processing of high-dimensional and graph-structured data, furthering generative models’ capabilities. Quantum computing’s ability to process data sets with high variability can also help to model interactions between molecules in a more realistic manner, enabling researchers to more accurately forecast the reactivity and safety of these molecules.
Generative modeling is entering an exciting new phase that will transform the biomedical engineering field; however, current developments within generative modeling uncover a small portion of their total potential. Further ongoing research into this field could uncover possible solutions to chronic diseases or pains, and GANs is likely to make its mark in multiple fields in due time. Perhaps in the future, when you take a painkiller to cure that incessant school headache, a computer would be to thank for giving you that peace of mind.